Troubleshooting
Here we provide help for some of the problems that you may encounter when using DataChain Studio.
Support
If you need further help, you can send us a message using the Help option on the DataChain Studio
website. You can also email us, create a
support ticket on GitHub, or join
the discussion in our community Discord.
Projects and experiments
- Errors accessing your Git repository
- Errors related to parsing the repository
- Errors related to DVC remotes and credentials
- Error: No DVC repo was found at the root
- Error: Non-DVC sub-directory of a monorepo
- Error: No commits were found for the sub-directory
- Project got created, but does not contain any data
- Project does not contain the columns that I want
- Project does not contain some of my commits or branches
- Error: Missing metric or plot file(s)
- Project does not display live metrics and plots
- Project does not display DVC experiments
- Error:
dvc.lockvalidation failed - Project does not reflect updates in the Git repository
Jobs
- Job stuck in QUEUED state
- Job fails during INIT
- Job fails during execution
- Storage access errors
- Job performance issues
Model registry
- I cannot find my desired Git repository in the form to add a model
- Model registry does not display the models in my Git repositories
- My models have disappeared even though I did not remove (deprecate) them
Billing and payment
Errors accessing your Git repository
When DataChain Studio cannot access your Git repository, it can present one of the following errors:
- Repository not found or you don't have access to it
- Unable to access repository due to stale authorization
- Unable to access repository
- Could not access the git repository, because the connection was deleted or the token was expired
- No tokens to access the repo
- Insufficient permission to push to this repository
- No access to this repo
To fix this, make sure that the repository exists and you have access to it. Re-login to the correct Git account and try to import the repository again. If you are connecting to a GitHub account, also make sure that the DataChain Studio GitHub app is installed.
Additionally, network or third party issues (such as GitHub, GitLab or Bitbucket outages) can also cause connection issues. In this case, DataChain Studio can display an appropriate indication in the error message.
Errors related to parsing the repository
If you see one of the following errors, it means that for some reason, parsing of the Git repository could not start or it stopped unexpectedly. You can try to import the repo again.
- Failed to start parsing
- Parsing stopped unexpectedly
Errors related to DVC remotes and credentials
DataChain Studio can include data from data remotes in your project. However, it can access data from network-accessible remotes such as Amazon S3, Microsoft Azure, etc but not from local DVC (acquired by lakeFS) remotes. If your project uses an unsupported remote, you will see one of the following errors:
- Local remote was ignored
- Remote not supported
Please use one of the following types of data remotes: Amazon S3, Microsoft Azure, Google Drive, Google Cloud Storage and SSH.
If the data remotes have access control, then you should add the required credentials to your project. If credentials are missing or incorrect, you will see one of the following errors:
- No credentials were provided
- Credentials are either broken or not recognized
- No permission to fetch remote data
Errors related to DVC remotes behind firewall
For self-hosted S3 storage(like Minio) or SSH server, ensure that it is available to access from the internet. If your server is behind the firewall, you can limit the traffic on the firewall to the server to allow access from our IP addresses only, which are:
Additionally, if you provide the hostname, the DNS records associated with the storage server should be publicly available to resolve the server name. Use DNS Propagation Checker to confirm if the server domain is resolvable. If you still have any trouble setting up the connection to your server, please contact us.
Error: No DVC repo was found at the root
If you get this message when you try to add a project:
No DVC repo was found at the root, then it means that you have connected to a
Git repository which contains a DVC repository in some sub-directory but not at
the root.
This could be a typical situation when your DVC repository is part of a monorepo.
To solve this, you should specify the full path to the sub-directory that contains the DVC repo.
Note that if you're connecting to a repository just to fetch models for the model registry, and you are not working with DVC repositories, you can ignore this error.
Error: Non-DVC sub-directory of a monorepo
If you get this message when you try to add a project:
Non-DVC sub-directory of a monorepo, then it means that you have connected to
a Git repository which contains a DVC repository in some sub-directory, but you
have selected the incorrect sub-directory.
This could be a typical situation when your DVC repository is part of a monorepo. Suppose your Git repository contains sub-directories A and B. If A contains the DVC repository which you want to connect from DataChain Studio, but you specify B when creating the project, then you will get the above error.
To solve this, you should specify the full path to the correct sub-directory that contains the DVC repo.
Error: No commits were found for the sub-directory
If you get this message when you try to add a project, then it means that you have specified an empty or non-existent sub-directory.
To solve this, you need to change the sub-directory and specify the full path to the correct sub-directory that contains the DVC repo.
Project got created, but does not contain any data
If you initialized a DVC repository, but did not push any commit with data, metrics or hyperparameters, then even though you will be able to connect to this repository, the project will appear empty in DataChain Studio. To solve this, make relevant commits to your DVC repository.
Refer to the DVC documentation for help on making commits to a DVC repository.
Note that if you're connecting to a repository just to fetch models for the model registry, and your repository is not expected to contain experiment data, metrics or hyperparameters, your project will appear empty. This is ok - you will still be able to work with your models in the model registry.
Project does not contain the columns that I want
There are two possible reasons for this:
- The required columns were not imported: DataChain Studio will only import columns that you select in the Columns setting.
What if the repository has more than 500 columns? Currently DataChain Studio
does not import over 500 columns. If you have a large repository (with more
than 500 columns), one solution is to split the
metrics/
To create projects for subdirectories, specify the project directory in project settings.
If this solution does not work for your use case, please create a support ticket in the DataChain Studio support GitHub repository.
- The required columns are hidden: In the project's experiment table, you can hide the columns that you do not want to display. If any column that you want is not visible, make sure you have not hidden it. The following video shows how you can show/hide columns. Once you show/hide columns, remember to save the changes.
#### Show/hide columns
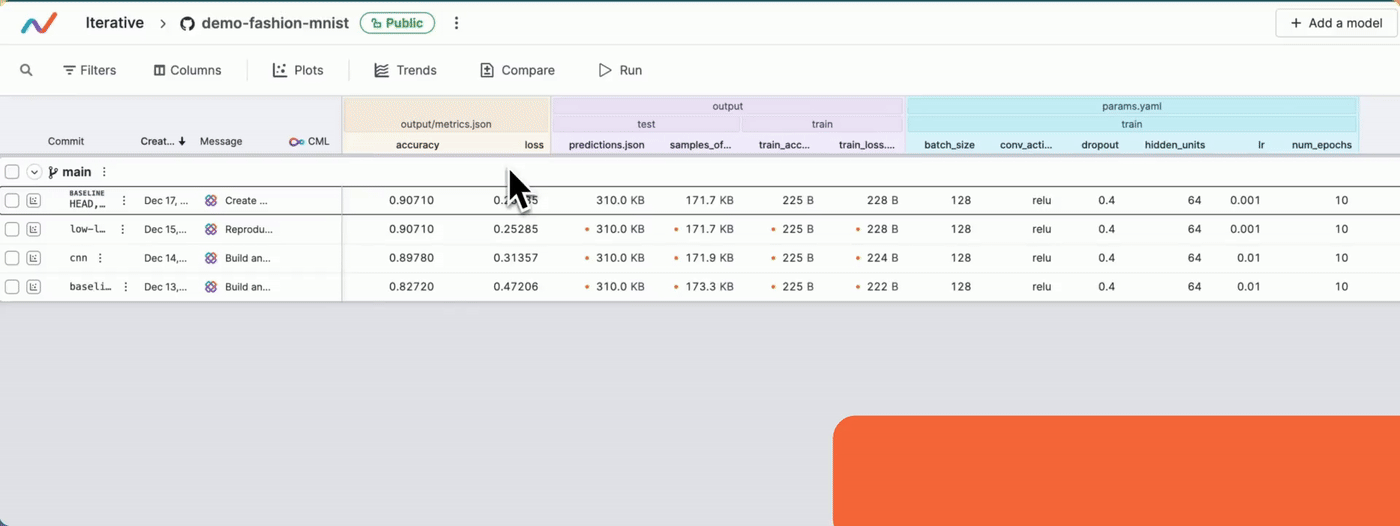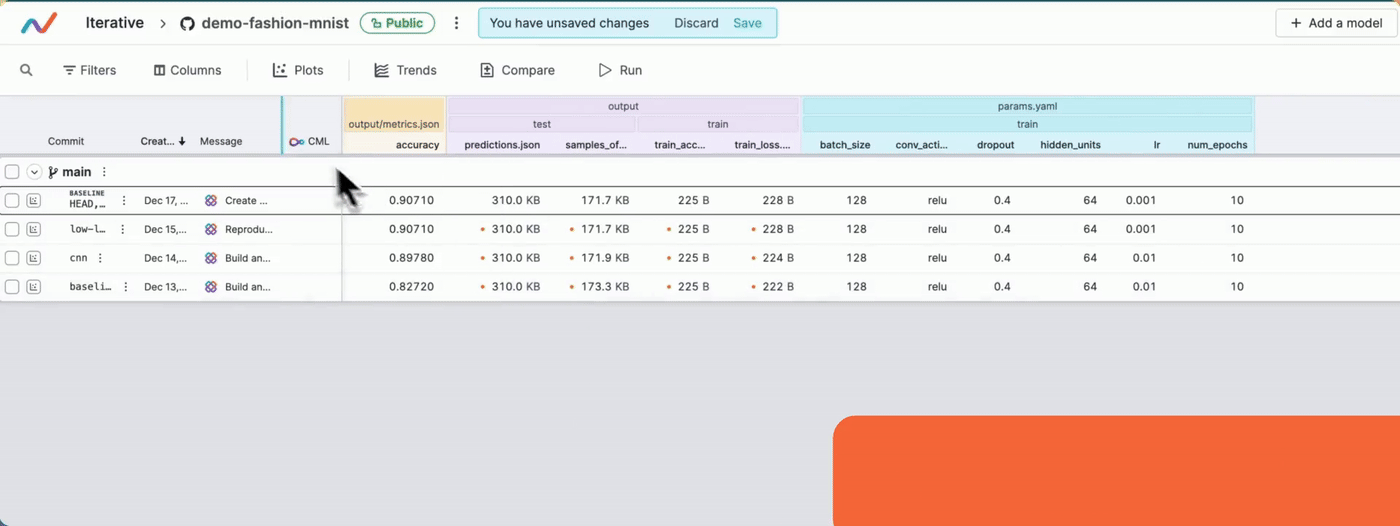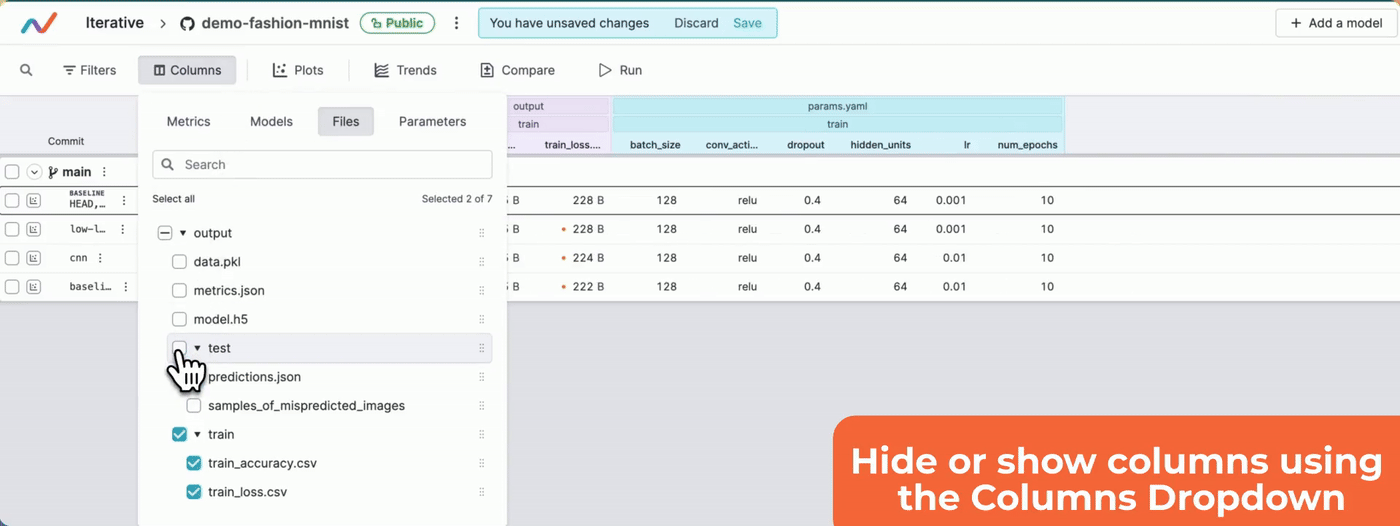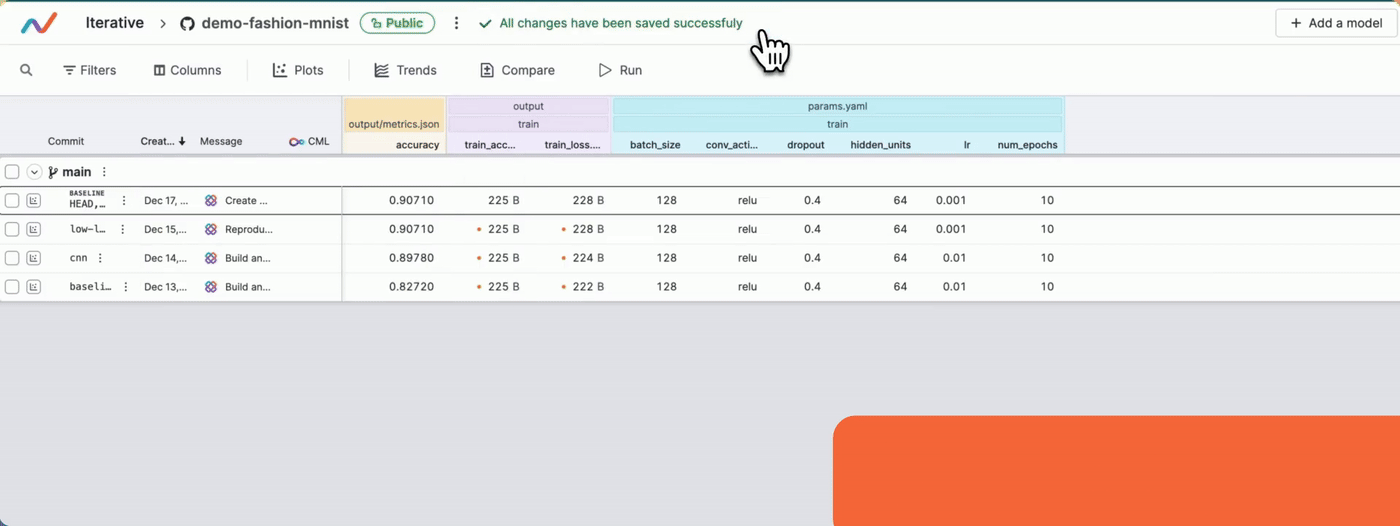
Project does not contain some of my commits or branches
This is likely not an error. DataChain Studio identifies commits that do not change
metrics, files or hyperparameters and will auto-hide such commits. It also
auto-hides commits that contain the string [skip studio] in the commit
message. You can also manually hide commits and branches, which means it is
possible that the commits or branches you do not see in your project were
manually hidden by you or someone else in your team.
You can unhide commits and branches to display them. For details, refer to Display preferences -> Hide commits. However, if the missing commit/branch is not in the hidden commits list, please raise a support request.
Error: Missing metric or plot file(s)
This error message means that the metric or plot files referenced from
dvc.yaml could not be found in your Git repository or cache. Make sure that
you have pushed the required files using dvc push. Then try to import the
repository again.
Error: Skipped big remote file(s)
Files that are larger than 10 MB are currently skipped by DataChain Studio.
Project does not display live metrics and plots
Confirm that you are correctly following the procedure to send live metrics and plots to DataChain Studio.
Note that a live experiment is nested under the parent Git commit in the project
table. If the parent Git commit is not pushed to the Git repository, the live
experiment row will appear within a Detached experiments dummy branch in the
project table. Once you push the missing parent commit to the Git remote, the
live experiment will get nested under the parent commit as expected.
Project does not display DVC experiments
DataChain Studio automatically checks for updates to your repository using webhooks,
but it can not rely on this mechanism for custom Git objects, like DVC
experiment references. So the experiments you push using dvc exp push
may not automatically display in your project table.
To manually check for updates in your repository, use the Reload button 🔄
located above the project table.
Error: dvc.lock validation failed
This error indicates that the dvc.lock file in the given commit has an invalid
YAML. If the given commit is unimportant to you, you can ignore this error.
One potential cause for this error is that at the time of the given commit, your repository used DVC 1.0. The format of lock files used in DVC 1.0 was deprecated in the DVC 2.0 release. Upgrading to the latest DVC version will resolve this issue for any future commits in your repository.
Project does not reflect updates in the Git repository
When there are updates (new commits, branches, etc.) in your Git repository,
your project in DataChain Studio gets reflected to include those updates. If the
project has stopped receiving updates from the Git repository and you have to
re-import the project each time to get any new commit, then it is possible
that the DataChain Studio webhook in your repository got deleted or messed up.
DataChain Studio periodically checks for any missing or messed up webhooks, and attempts to re-create them. Currently, this happens every 2 hours. The webhook also gets re-created every time you create a new project or re-import a repository.
Job stuck in QUEUED state
If your job remains in the QUEUED state for an extended period:
Possible Causes
- No available workers: All workers in the cluster are busy processing other jobs
- Resource quotas exceeded: Your team has reached the maximum number of concurrent jobs
- High priority jobs ahead: Other jobs with higher priority are being processed first
Solutions
- Check the worker availability in the status bar at the top of Studio
- Review your team's resource quotas and usage
- Consider adjusting job priority settings if appropriate
- Wait for currently running jobs to complete
- Contact support if jobs remain queued for unusually long periods
Job fails during INIT
If your job fails during the initialization phase:
Common Causes
- Invalid package requirements: Errors in requirements.txt file
- Incompatible package versions: Package version conflicts
- Missing dependencies: Required packages not specified
Solutions
- Check the Logs tab for specific error messages about package installation
- Review your requirements.txt file:
- Verify package names are spelled correctly
- Check for version compatibility between packages
- Pin package versions to avoid conflicts (e.g.,
pandas==2.0.0) - Test package installation locally before submitting the job
- Minimize the number of dependencies to reduce initialization time
- Check the Dependencies tab in job monitoring to see what was installed
Example of Common Issues
Bad requirements.txt:
pandas
numpy===1.24.0 # Three equals signs - syntax error
pillow>=9.0.0,<10.0.0
invalipakage # Typo in package name
Good requirements.txt:
Job fails during execution
If your job starts running but fails during data processing:
Script Errors
- Syntax errors: Check your Python code for syntax issues
- Logic errors: Review your DataChain operations for logical mistakes
- Unhandled exceptions: Add proper error handling to your script
Data Access Issues
- Invalid storage paths: Verify that storage paths are correct and accessible
- Missing credentials: Ensure storage credentials are configured in account settings
- Permission denied: Check that your credentials have the necessary permissions
- Storage path not found: Verify the bucket/container and path exist
Resource Limits
- Out of memory: Job exceeded allocated memory
- Solution: Reduce batch size, increase workers, or process data in chunks
- Timeout: Job took longer than maximum allowed time
- Solution: Optimize code or split into smaller jobs
- Storage full: Temporary storage filled up
- Solution: Clean up intermediate files or reduce data volume
Debugging Steps
- Check the Logs tab: Look for error messages and stack traces
- Review the Diagnostics tab: Check which phase failed and execution timeline
- Check the Dependencies tab: Verify data sources are connected correctly
- Test with a subset: Try running with a smaller sample of data
- Run locally: Test your script locally with sample data before submitting
Storage access errors
If you encounter errors accessing cloud storage:
Credential Issues
- No credentials configured: Add storage credentials in account settings
- Expired credentials: Refresh or update your credentials
- Wrong credentials: Verify you're using the correct credentials for the storage
Permission Issues
- Insufficient permissions: Your credentials don't have read access to the storage
- Bucket not found: Storage bucket/container name is incorrect
- Path not accessible: The specific path within storage doesn't exist
Network Issues
- Connection timeout: Network connectivity problems between Studio and storage
- Firewall blocking: Storage is behind a firewall that blocks Studio's IP addresses
Solutions
- Verify credentials are configured correctly in account settings
- Check storage bucket permissions and access policies
- Test storage connection separately before running the job
- Ensure storage path exists and is accessible
- For self-hosted storage, verify firewall allows access from Studio's IP addresses:
Job performance issues
If your jobs are running slower than expected:
Analyzing Performance
Check the Diagnostics tab to identify bottlenecks:
Long Queue Times (> 2 minutes)
- Cause: High cluster demand or insufficient available workers
- Solution:
- Run jobs during off-peak hours
- Consider upgrading to a plan with more workers
- Adjust job priority for urgent tasks
Long Worker Start (> 5 minutes)
- Cause: Cold start of compute resources
- Solution:
- This is typically infrastructure-related
- Contact support if consistently slow
Slow Dependency Installation (> 3 minutes)
- Causes:
- Many packages to install
- Large package downloads
- Package version resolution conflicts
- Solutions:
- Pin package versions in requirements.txt to avoid resolution
- Minimize number of dependencies
- Use cached virtualenv when possible (shown in Logs)
Extended Data Warehouse Wake (> 2 minutes)
- Cause: Infrastructure initialization
- Solutions:
- Keep warehouse warm by running jobs regularly
- Contact support for dedicated warehouse options
Long Running Query Time
- Causes:
- Processing large volumes of data
- Inefficient DataChain operations
- Insufficient workers for dataset size
- Solutions:
- Filter data early to reduce processing volume
- Use efficient DataChain operations (avoid unnecessary transformations)
- Increase worker count for large datasets
- Batch operations appropriately
- Profile your code to identify slow operations
General Performance Tips
- Start small: Test with a small data sample first
- Monitor metrics: Track job execution times across runs
- Use appropriate workers: Balance between cost and performance
- Optimize code: Profile and optimize DataChain operations
- Review logs: Check for warnings about performance issues
- Compare runs: Use the Diagnostics tab to compare execution times
For detailed monitoring guidance, see Monitor Jobs.
I cannot find my desired Git repository in the form to add a model
Only repositories that you have connected to DataChain Studio are available in the
Add a model form. To connect your desired repository to DataChain Studio, go to the
Projects tab and create a project that connects to this Git
repository. Then you can come back to the model registry and
add the model.
Model registry does not display the models in my Git repositories
For a model to be displayed in the model registry, it has to be added using DVC.
My models have disappeared even though I did not remove (deprecate) them
When a project is deleted, all its models get automatically removed from the model registry. So check if the project has been removed. If yes, you can add the project again. Deleting a project from DataChain Studio does not delete any commits or tags from the Git repository. So, adding the project back will restore all the models from the repository along with their details, including versions and stage assignments.
Questions or problems with billing and payment
Check out the Frequently Asked Questions to see if your questions have already been answered. If you still have problems, please contact us.